Google Code Jam 2018: Practice session results
If you’re not familiar with Google Code Jam, it’s a yearly competition organized by Google where contestants compete in solving programming problems. You are given a problem and some limitations, e.g. only a few hours to prepare solutions in later stages of the event, runtime and memory constraints for programs. It’s a fairly popular contest, bringing in thousands of participants from all over the world, with World Finals taking place in Toronto and the best contestant taking home a $15,000 grand prize, fame and glory.
In the practice session of 2018 there were 4 problems and 2 days were given to solve them. You can find the full list of problems and their descriptions HERE.
1. Number Guessing
Here’s the full problem description.
But in short, the judge program comes up with a secret number in a given range and allows you to make no more than a specific number of guesses. Your program has to guess what the number is, and after each guess the judge will respond with “TOO_BIG”, “TOO_SMALL” or “CORRECT”. If your program fails to guess the number correctly, the judge will respond with “WRONG_ANSWER” and will stop replying.

This immediately sounds like binary search, doesn’t it? You have to guess a number in 1-dimensional space, and the only feedback judge provies is if we guessed to high or too low. So the best we can do is to always guess in the middle of the available space, discarding the half where we know our target is not in. Based on the image example above, it would take 4 guesses to find the right answer using this strategy: binary search has an average performance of O(log(n)).
My first stumble was in picking the right midpoint. Initial one was the average of lower and upper bounds midpoint = (lower_bound + upper_bound) // 2.
Integer division is there to avoid producing a decimal number (e.g. (1 + 4) / 2 == 2.5, but (1 + 4) // 2 == 2).
This passed the testing_tool.py, but failed hidden tests, failing to find the answer in required number of guesses.
Wiki article also suggests using floor of (lower_bound + upper_bound) / 2, but taking ceil instead passed the tests: midpoint = (lower_bound + upper_bound + 1) // 2.
The second stumble was in not terminating the program as specified when the judge responded with WRONG_ANSWER. It wasn’t quite clear whether on the last answer it would respond with TOO_BIG and then WRONG_ANSWER, or just WRONG_ANSWER, so I covered for both, yielding this code:
def run():
test_cases = read_int()
for case in range(test_cases):
case += 1
[lower_bound, upper_bound] = read_ints()
guesses = read_int()
guessed_right = False
for guess in range(guesses):
midpoint = (lower_bound + upper_bound + 1) // 2
write_guess(midpoint)
answer = read_answer()
if answer == TOO_BIG:
upper_bound = middle
elif answer == TOO_SMALL:
lower_bound = middle
elif answer == CORRECT:
guessed_right = True
break
elif answer == WRONG_ANSWER:
exit()
if guessed_right == False:
answer = read_answer()
exit()
I skipped definitions for read_int(), read_ints(), read_answer(), write_guess() - they’re basic stdin and stdout operations.
2. Senate evacuation
Here’s the full problem description.
In short, there are a number of political parties in senate with some number of senators in each party. We want to evacuate all senators in such a way that neither party has the majority at any step (>50% of senators still in senate), while we can evacuate only one or two senators at a time.
Or to rephrase the problem slightly differently: we have a list of integers, we can subtract 1 or 2 at a time from any member in such a way that neither member is bigger than 50% of sum of all members. Let’s start with checking the current state for validity and encode this rephrased version in code:
def is_valid(senators):
total_senators = sum(senators)
limit = total_senators / 2
return all(map(lambda p: p <= limit, senators))
For the strategy itself, initial hunch suggests to attack parties with most senators first. We will always be able to evacuate at least one senator.
As for the second one, after selecting the first candidate we can check again which party has most members. If after removing it the state is still legal (using is_valid()) - then we can take two senators. If not - we have to take just one.
We just have to take into account a case when there are no senators left at all ([0, 0, ..., 0]), or just one ([1, 0, 0, ..., 0]).
In code this idea can be written as:
def solve(parties, senators):
solution = []
most_senators = max(senators)
while most_senators > 0:
first_target = senators.index(most_senators)
senators[first_target] -= 1
second_largest_party = max(senators)
second_target = senators.index(second_largest_party)
senators[second_target] -= 1
if second_largest_party == 0 or not is_valid(senators):
# Can take only one senator, must put second one back
solution.append(alphabet[first_target])
senators[second_target] += 1
else:
# Can take both senators
solution.append(alphabet[first_target] + alphabet[second_target])
most_senators = max(senators)
return solution
And to transform political party numbers back into alphabetical party names: alphabet = dict(enumerate('ABCDEFGHIJKLMNOPQRSTUVWXYZ')).
With final run() written as:
def run():
test_cases = read_int()
for case in range(test_cases):
case += 1
N = read_int()
senators = read_ints()
solution = solve(N, senators)
write_answer('Case #%d: %s' % (case, ' '.join(solution)))
3. Steed 2: Cruise Control
Here’s the full problem description.
In short, on a one-way road there are a number of horses with some initial positions and all travelling in the same direction at some individual speeds. However, these horses move in a special way in that they cannot pass each other. So if one catches up to another, they’ll both continue travelling at the slower one’s speed. Our hero wants to travel to a specific point on the same road and has to abide same rules of not passing another horse. The hero can travel at any speed, but wants to maintain a constant speed throughout the full travel without having to speed up or slow down. What is the maximum speed the hero can choose?
The first hunch was to try and calculate for how long each horse will travel at what speed, and try to deduce hero’s target speed from that. But the problem mentions that it may use up to 1000 horses. At least we can imagine describing a situation where we put fastest horses at the start, and slowest ones near the end, and faster horses gradually running into slower ones. It quickly becomes a complex mess.
The second idea was to compute how long it will take for each horse to get to hero’s destination, but do it from right to left. Right to left, because horses to the right will always be limiting factors - horses to the left can’t get to the destination faster than the horse to the right, they’d eventually catch up and will have to slow down, so their journey will take at least as long as the horse’s to the right. And turns out that this approach allows for fairly straightforward linear computation.
So for each horse we compute how long it would take them to cover the remaining distance from their starting point to the destination.
If we take the max() of these durations, that will give us our hero’s travel duration.
From there we can find the average speed with average_speed = distance / duration.
def solve(distance, total_horses, horses):
longest_duration = max(map(lambda h: (distance - h[0]) / h[1], horses.values()))
return distance / longest_duration
def run():
test_cases = read_int()
for case in range(test_cases):
case += 1
[distance, total_horses] = read_ints()
horses = {}
for i in range(total_horses):
[initial, max_speed] = read_ints()
horses[i] = [initial, max_speed]
# print([distance, total_horses, horses])
solution = solve(distance, total_horses, horses)
write_answer('Case #%d: %.7f' % (case, solution))
4. Bathroom Stalls
Here’s the full problem description.
In short, there are N+2 bathroom stalls, with first and last one already occupied. A number of people will come in one after another, selecting a stall and never leaving. People will select a stall that is furthest from its closest neighbors. The goal is to find out, when the last person takes a stall, what’s the largest and lowest number of free stalls next to the side of it.
This one was rough, taking about 4 hours to figure out, but in the end the solution was mathematical and fairly elegant, at least in my eyes.
The initial idea would be to maybe try and write a program that puts people in the appropriate stalls sequentially one by one. But the problem arises from constraints: the number of stalls can be as large as 10^18, and number of people can be equal to the number of stalls.
How would such data structure be represented? If we represented each stall as 1 byte, that’s still 10^18 bytes - exabyte, for comparison a gigabyte is about 10^9, so there’s no way we’re storing this much information, in memory or on disk.
northeastern.edu suggests that in 2013 total amount of data in the world was 4.4 zettabytes, or 4400 exabytes. We certainly won’t dedicate 0.2% of world’s storage to solve this problem.
And If each stall was represented as a bit, divide the numbers by 8, but they’re still gargantuan and unmanageable numbers.
Especially note that the execution time limit is 30 seconds. Which suggests there has to be a better way.
The next idea was that maybe it could be related to fractals - similar repeating patterns at different scales. E.g. Here’s how 7 stalls would be filled up:
1|2|3|4|5|6|7 1|2|3|4|5|6|7
------------- -------------
_|_|_|1|_|_|_ _|_|_|1|_|_|_
_|2|_|_|_|_|_ _|2|_|1|_|_|_
_|_|_|_|_|3|_ _|2|_|1|_|3|_
4|_|_|_|_|_|_ 4|2|_|1|_|3|_
_|_|5|_|_|_|_ 4|2|5|1|_|3|_
_|_|_|_|6|_|_ 4|2|5|1|6|3|_
_|_|_|_|_|_|7 4|2|5|1|6|3|7
Maybe the same pattern that governs selection of one could be repeated on its left branch to position 2, resulting maybe in a tree of sorts. But that still does not suggest a way how to determine number of free stalls on each position’s side. So the third option was to brute force and write down free stall numbers for each N.
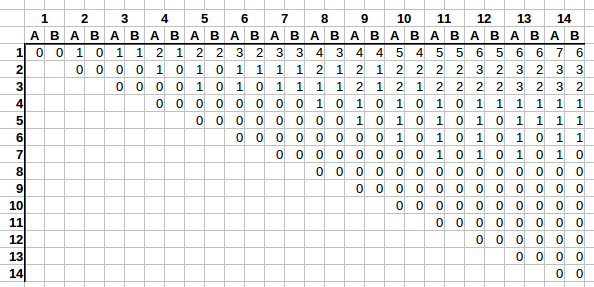
In the graph the columns denote N - how many stalls there are. Rows denote how many people have already selected a stall.
And (stalls, people) combination denotes A - the largest number of stalls available next to last person’s stall, and B - the lowest number of stalls next to the last selected stall.
Right away we see an interesting trend. E.g. take a look at the first row. As columns grow from left to right, first A increases by one, then B catches up on the next column. And it repeats.
On the second row it’s very similar. First A increases by one, then B catches up, but this rate of change is slower, only every two columns as opposed to with every one.
It’s getting difficult to follow, as we’re running out of columns to clearly see the trend, but on the fourth row the rate of change is even slower, with A and B incrementing only once every 4 columns.
Let’s add some visual aid:
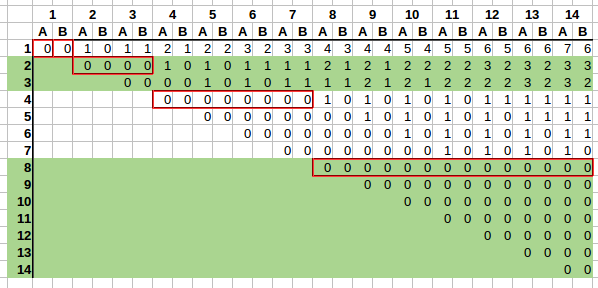
It would be a bit clearer if we had 16 rows and 16 columns, but this suffices to spot the trend.
We can see that rate of change also changes based on the row, and such rates of change can be grouped based on powers of two:
2^0 = 1- one row will change on every column;2^1 = 2- there are 2 rows in the group, soAandBwil change every 2 columns on rows2and3;2^2 = 2- there are 4 rows in the group,AandBwill change every4columns on rows4-7;2^3 = 8- there are 8 rows in the group,AandBwill change every8columns on rows8-15;
And so on. We have found a pattern. Now how to calculate A and B if we are given the row and column number?
Rate of change
First we need to find every how many columns A and B changes based on the row. Since groups grow as powers of two, we could take floor(log2(row)) to find in which group a row is.
E.g. floor(log2(9)) = 3, which means we are in the fourth group (indexed from 0, see list above). If we raise the base 2 back to the power of 3 - this gives us rate of change 8, which is what we would expect as per our pattern we’ve seen above.
So the derived formula for rate of change seems to be rate_of_change = lambda row: 2 ** math.floor(math.log2(row))
How many changes already occurred
Next we need to find out how many changes have occurred based on the column number. We can see that A and B always change in the following pattern:
0 0 -> 1 0 -> 1 1 -> 2 1 -> 2 2 -> 3 2 -> 3 3 -> ... -> x+1 x -> x+1 x+1 -> ...
So based on rate of change we can count how many changes have already occurred given a row and a column.
Taking a look at the stall positioning table again, for any row number, on which column does the row start?
We see that the row starts at the column number equal to the row number. E.g. row 4 starts at 4th column, row 9 starts at 9th column.
So if we check how many rate_of_change columns fit in this space - that will tell us how many changes have already occurred.
E.g. for row=3, column=6, the rate of change is 2 ** math.floor(math.log2(3)) == 2.
Row 3 starts at column 3, and we’re interested in column 6. 6-3 leaves a space of 3 for changes to occur in.
If we divide that by rate_of_change = 2 => (6 - 3) / 2 = 1.5. So a full one change has already occurred, going 0 0 -> 1 0.
If you check the table again, we see that this is exactly right.
So the derived formula seems to be number_of_changes_done = lambda column, row: math.floor((column - row) / rate_of_change(row))
Putting it all together: calculating A and B
Now we can calculate A and B.
If we take a look at the first line, we see that A number seems to be equal to about half of the number of changes for a specific column.
E.g. on row=1 column=3, the result we are aiming for is A=1, B=1, and a total of 2 changes have already occurred.
Or on row=1 column=10, the result we are aiming for is A=5, B=4, and a total of 9 changes have already occurred.
And B tends to also be about half of the number of changes for a specific column, but always either equal to A, or one less than A.
So my idea was to use ceil and floor, setting A = math.ceil(number_of_changes_done / 2), and B = number_of_changes_done - A, and this seems to work.
E.g. row=1 column=3: number_of_changes_done = 2, A = math.ceil(2 / 2) => math.ceil(1) => 1, B = 2 - 1 => B = 1.
Or row=6, column=14: number_of_changes_done = 2, A = math.ceil(2 / 2) => math.ceil(1) => 1, B = 2 - 1 => B = 1.
Or row=2, column=11: number_of_changes_done = 4, A = math.ceil(4 / 2) => math.ceil(2) => 2, B = 4 - 2 => B = 2.
The formulas seem to check out!
Final code
def get_change_rate_on_row(K):
# Every how many records do values change on row K
return 2 ** math.floor(math.log2(K))
def number_of_changes_done(N, K):
return math.floor((N - K) / get_change_rate_on_row(K))
def solve(N, K):
change_rate = get_change_rate_on_row(K)
total_changes = number_of_changes_done(N, K)
y = math.ceil(total_changes / 2)
z = total_changes - y
return [str(y), str(z)]
def run():
test_cases = read_int()
for case in range(test_cases):
case += 1
[stalls, people] = read_ints()
solution = solve(stalls, people)
# print(case, solution)
write_answer('Case #%d: %s' % (case, ' '.join(solution)))
All this work for a straight forward calculation!
But there we go, we have calculated values A and B for any given row and column in a fraction of a second and without using 0.02% of world’s data storage capacity.
Final thoughts
The final result ended up being:
- Place: 661/4199
- Score: 60
- Problem 1: 2/2
- Problem 2: 2/2
- Problem 3: 2/2
- Problem 4: 2/3. Last test with 1 <= N <= 10^18 failed with “Wrong answer”. Unfortunately data is not published, so I can’t check what happened, especially at that scale.
But overall it’s been a fun brain teaser. The last problem was especially challenging, but that made it so much more satisfying to crack.
The first problem seemed like a clear approach for binary search, but I was unable to think of any metaphors or similar problems for the other three. I managed to muddle through them, but seeing how quickly other contestands were able to breeze through these problems, that makes me think that there are other relatable problems or approaches one could use here. Have you solved these problems? What approach did you take? I’d be curious to learn more.
And if you haven’t tried Google Code Jam or similar competitions before - give it a go some time. They can twist your brain unlike daily CRUD apps, making us more capable of solving more complex problems in the end.
Subscribe via RSS