Building a Reinforcement Learning bot for Bubble Shooter with Tensorflow and OpenCV
TL;DR: Here is some resulting gameplay from this Dueling Double Deep Q-learning network based bot:
For a while I wanted to explore Reinforcement learning, and this time I’ve done so by building a Q-Learning based bot for the Bubble Shooter game - an Adobe Flash based game running in the browser.
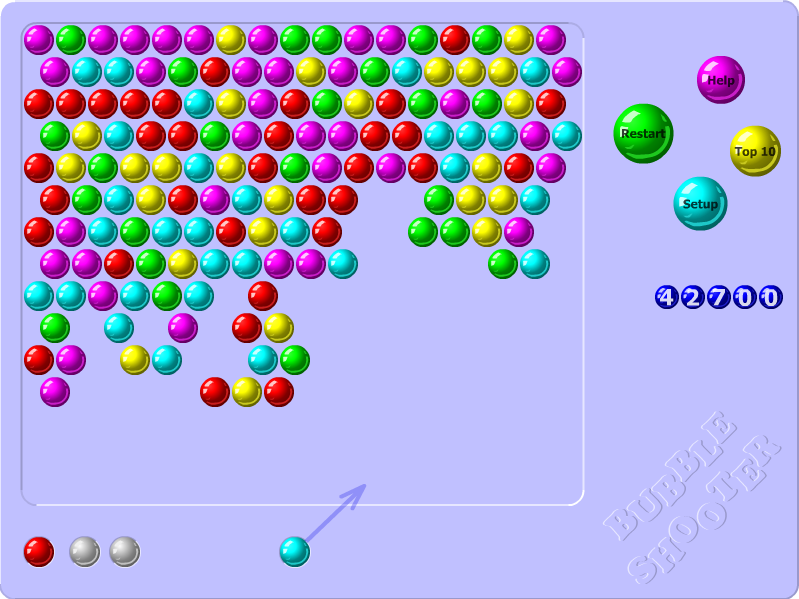
The game works as follows: the game board contains bubbles of 6 different colors. Shooting a connected group of same colored bubbles with 3 or more bubbles in it destroys all of them. The goal of the game is to destroy all bubbles on the board.
I chose the game for simplicity of its UIs and 1-click gameplay, which was reasonably straightforward to automate.
What is Q-Learning?
You can learn about it in more detail by reading this Wikipedia article or watching this Siraj Raval’s explanatory video.
But in short, in Q-Learning given a state the agent tries to evaluate how good it is to take an action. The “Q” (or “Quality”) value depends on the reward the agent expects to get by taking such action, as well as in any future states.
E.g. maybe the agent shoots a bubble in one place and doesn’t destroy any bubbles - probably not a great move. Perhaps it shoots a bubble and manages to destroy 10 other bubbles - better! Or perhaps it does not destroy any bubbles on the first shot, but this enables the agent to destroy 20 bubbles with the second shot and win the game.
The agent chooses its moves by calculating Q-values for every possible action, and choosing the one with the largest Q-value - the move it thinks will provide it with the most reward.
For simple cases with few unique game states one can get away with a table of Q-values, but state of the art architectures switched to using Deep Neural Networks to learn and predict the Q-values.
Dueling Double Q Network architecture
The simplest case is a Deep Q Network - a single deep neural net that attempts to predict the Q-value of every step. But apparently it is prone to overestimation, resulting in the network thinking the moves are better than they really are.
An improvement of that was Double Q Network (Arxiv paper: Deep Reinforcement Learning with Double Q-learning), which has two neural networks: an online one and a target one. The online network gets actively trained, while the target one doesn’t, so the target network “lags behind” in its Q-value evaluations. The key is that the online network gets to pick the action, while the target network performs the evaluation of the action. The target network gets updated every so often by copying the Neural Network weights over from the online network.
A further improvement still was a Dueling Q network (Arxiv paper: Dueling Network Architectures for Deep Reinforcement Learning). The idea here is that it splits out the network into 2 streams: advantage and value, results of which are later combined into Q-values. This allows the network to learn which states are valuable without having to learn the effect of every action in the state, allowing it to generalize better.
In the end I’ve ended up combining all of the techniques above into the following network:
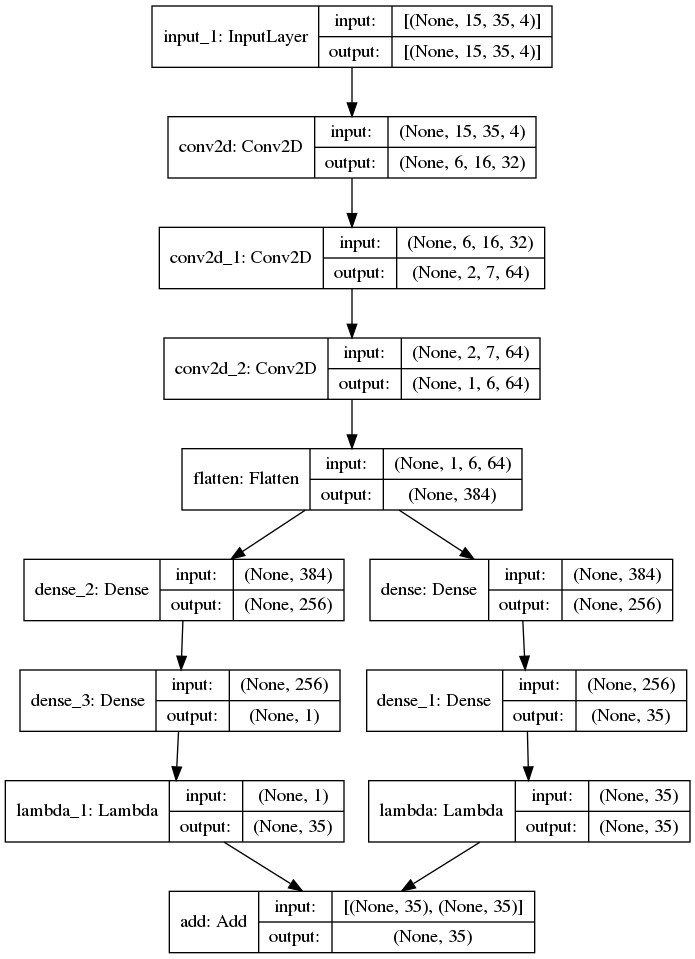
It’s based on the architecture mentioned in one of the papers: several convolutional layers followed by several fully connected layers.
Game states and rewards
DeepMind were able to get their model successfully playing 2600 Atari games just by taking game screenshots as an input to the neural net, but for me the network simply failed to learn anything. Well, aside from successfully ending the game in the fewest number of steps.
So I ended up using Computer Vision to parse the game board into a 35x15 matrix. 35 ball halves fit horizontally, and 15 balls fit vertically into a game board, so every cell in a matrix represents a half-ball horizontally and a full-ball vertically.
What the current agent actually sees though are 4 different snapshots of the game board:
- Positions of half-balls that match the current ball’s color
- Positions of half-balls that don’t match the current ball’s color
- Positions of half-balls that match the next ball’s color
- Positions of half-balls that don’t match the next ball’s color

The idea was to start with at least learning the game for the current and the following ball colors to simplify the rules. I tried having layers for balls of every color, but wasn’t able to make it work yet.
For rewards, I’ve settled on two: destroying more than one ball gives a reward of 1, every other action gives a reward of 0. Otherwise I found that Q-values gradually grow to infinity.
For possible actions, the game board is 500x500 px in dimensions, meaning that there are 250000 possible actions for every state, that means lots of computations. To simplify, I’ve narrowed the action space down to 35 different actions, all oriented in a single horizontal line ~100px from the bottom of the game board.
This makes some further shots impossible due to lack of accuracy, but seems to be good enough to start with.
Prioritized experience replay
The first option is to start with no replay at all. The agent could take a step and learn from it only once. But it is a poor option, as important experiences may be forgotten, and adjacent states correlate with each other.
An improvement over it was to keep some recent experiences (e.g. 1 million experiences), and to train the neural network based on a randomly sampled batch of experiences. This allows to avoid correlation of adjacent states, but important experiences may still end up being revisited rarely.
A further improvement over that is to keep a buffer of prioritized experiences. The experiences are prioritized based on the Q-value error (difference of predicted Q-value and actual Q-value), and training the neural network by sampling batches from different ranges of errors. That way more error-prone but rarely occurring states have a better chance of being retrained upon.
I ended up using Jaromiru’s (based on this article) reference implementation of Prioritized Experience Replay (SumTree, Memory).
An experience is a tuple of:
- The current state
- The action taken
- The reward received
- The next resulting state
- Whether the episode is “done”
Training in parallel
Originally I’ve started with just a single instance of the game for training, but Machine Learning really shines with lots and lots of data (millions, billions of samples - the more the better), so at 2-5 seconds per step it just took too long to get any substantial amount of training done.
So I used Selenium+Firefox and Python’s multiprocessing module to run 24 isolated game instances at once, allowing it to top out at about 4 steps/second. Even at the low number of instances it’s quite CPU-heavy and makes my poor Ryzen 2700x struggle, making the games run slower.
You can find an explanation on how it was done in my last post, or find the code on Github.
Results
The most successful hyperparameters so far were:
- Exploration probability (epsilon):
0.99 - Minimum exploration probability:
0.1and gradually reducing to0.01with every training session - Exploration probability decay every episode:
0.999gradually reducing to0.9with every training session - Gamma:
0.9 - Learning rate:
0.00025 - Replay frequency: every
4steps - Target network update frequency: every
1000steps - Memory epsilon:
0.01 - Memory alpha:
0.6 - Experience memory buffer:
20000experiences - Batch size:
32
In total the model was trained about 6 different times for 200-300k steps - for ~24h each time.
During training the model on average takes ~40 steps (~70 max), and is able to destroy at least 2 bubbles ~19 times in an episode (~39 max).
The resulting gameplay is not terribly impressive, the agent is not taking some clear shots when there’s nothing better to do. Its knowledge also seems to be concentrated close to the starting state - it’s not doing well with empty spaces closer to the top or bottom of the board. But it is playing the game to some extent, and if the game’s RNG is favorable - it may even go pretty far.
As a next step I might try different network architectures and hyperparameters, to speed things up pretrained offline on the bank of experiences acquired from this model’s gameplay.
If you’re interested in the code, you can find it on Github.
Subscribe via RSS