Automating basic tasks in games with OpenCV and Python
In multiplayer games bots have been popular in giving an edge to players on certain tasks, like farming in-game currency in World of Warcraft, Eve Online, level up bots for Runescape. As a technical challenge it can be as basic as a program to play Tic Tac Toe for you, or as complex as DeepMind and Blizzard using StarCraft II as their AI research environment.
If you are interested in getting your feet wet with Computer Vision, game automation can be an interesting and fairly easy way to practice: contents are predictable, well known, new data can be easily generated, interactions with the environment can be computer controlled, experiments can be cheaply and quickly tested. Grabbing new data can be as easy as taking a screenshot, while mouse and keyboard can be controlled with multiple languages.
In this case we will use the most basic strategy in CV - template matching. Of course, depends on the problem domain, but the technique can be surprisingly powerful. All it does is it slides the template image across the input image and compares differences. See Template matching docs for more visual explanation of how it works.
As the test bed I’ve chosen a flash game called Burrito Bison. If you’re not familiar with it - check it out. The goal of the game is to throw yourself as far as possible, squishing gummy bears along the way, earning gold, buying upgrades and doing it all over again. Gameplay itself is split into multiple differently themed sections, separated by giant doors, which the player has to gain enough momentum to break through.
It is a fairly straightforward game with basic controls and a few menu items. Drag the bison for it to jump off the ropes and start the game, left-click (anywhere) when possible to force smash gummy bears, buy upgrades to progress. No keyboard necessary, everything’s in 2D, happening on a single screen without the need for player to manually scroll. The somewhat annoying part is having to grind enough gold coins to buy the upgrades - it is tedious. Luckily it involves few actions and can be automated. Even if done suboptimally - quantity over quality, and the computer will take care of the tediousness.
If you are interested in the code, you can find the full project on Github.
Overview and approach
Let’s first take a look at what needs to be automated. Some parts may be ignored if they don’t occur frequently, e.g. starting the game itself, some of the screens (e.g. item unlocked). But can be handled if desired.
There are 3 stages of the game with multiple screens, multiple objects to click on. Thus the bot will sometimes need to look for certain indicators whether or not it’s looking at the right screen, or look for objects if it needs to interact with them. Because we are working with templates, any changes in dimensions, rotation or animations will make it more difficult to match the objects. Thus objects bot looks for have to be static.
1. Starting the round
The round is started by pushing the mouse button down on the bison character, dragging the character to aim and releasing it. If bison hit the “opponent” - a speed boost is provided.

There are several objects to think about:
- Bison itself. The bot will need to locate the bison character and drag it away to release it
- Whether or not the current screen is the round starting screen. Because the player character will occur elsewhere in the game, the bot may be confused and misbehave if we use the bison itself. A decent option could be to use ring’s corner posts or the “vs” symbol.
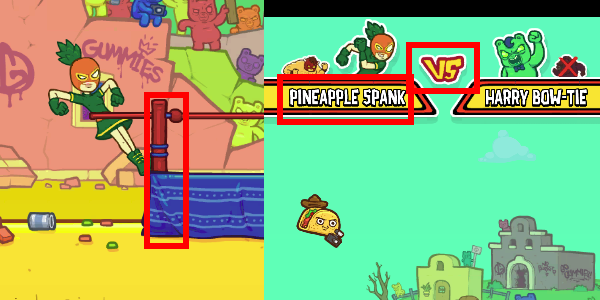
2. Round in progress
Once the round has started, the game plays mostly by itself, no need for bot interactions for the character to bounce around.

To help gain more points though we can use the “Rocket” to smash more gummies. To determine when rocket boost is ready we can use the full rocket boost bar as a template. Left mouse click anywhere on screen will trigger it.
3. Round ended
Once the round ends there are be a few menu screens to dismiss (pinata ad screen, missions screen, final results screen), and the bot will need to click a button to restart the round.
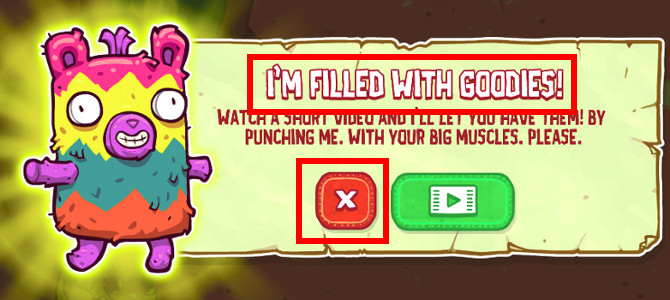
Pinata screen:
- we can use “I’m filled with goodies” text as the template to determine if we’re on the pinata screen. Pinata animation itself moves, glows, which may make it difficult for bot to match to template, thus unsuitable.
- “Cancel” button, so the bot can click it
Mission screen:
Simply match the “Tap to continue” to determine if we’re on this particular screen and left mouse click on it to continue.

Round results screen:
Here “Next” button is static and we can reliably expect it to be here based on game’s flow. The bot can match and click it.

Implementation
For vision we can use OpenCV, which has Python support and is the defacto library for computer vision. There’s plenty to choose from for controlling the mouse, but I found luck with Pynput.
Controls
As far as controls go, there are 2 basic actions bot needs to perform with the mouse: 1) Left click on a specific coordinate 3) Left click drag from point A to point B
Let’s start with moving the mouse. First we create the base class:
import time
from pynput.mouse import Button, Controller as MouseController
class Controller:
def __init__(self):
self.mouse = MouseController()
The Pynput library allows setting mouse position via mouse.position = (5, 6), which we can use. I found that in some games changing mouse position in such jumpy way may cause issues with events not triggering correctly, so instead I opted to linearly and smoothly move the mouse from point A to point B over a certain period:
def move_mouse(self, x, y):
def set_mouse_position(x, y):
self.mouse.position = (int(x), int(y))
def smooth_move_mouse(from_x, from_y, to_x, to_y, speed=0.2):
steps = 40
sleep_per_step = speed // steps
x_delta = (to_x - from_x) / steps
y_delta = (to_y - from_y) / steps
for step in range(steps):
new_x = x_delta * (step + 1) + from_x
new_y = y_delta * (step + 1) + from_y
set_mouse_position(new_x, new_y)
time.sleep(sleep_per_step)
return smooth_move_mouse(
self.mouse.position[0],
self.mouse.position[1],
x,
y
)
The number of steps used here is likely too high, considering the game should be capped at 60fps (or 16.6ms per frame). 40 steps in 200ms means a mouse position change every 5ms, perhaps redundant, but seems to work okay in this case.
Left mouse click and dragging from point A to B can be implemented using it as follows:
def left_mouse_click(self):
self.mouse.click(Button.left)
def left_mouse_drag(self, start, end):
self.move_mouse(*start)
time.sleep(0.2)
self.mouse.press(Button.left)
time.sleep(0.2)
self.move_mouse(*end)
time.sleep(0.2)
self.mouse.release(Button.left)
time.sleep(0.2)
Sleeps in between mouse events help the game keep up with the changes. Depending on the framerate these sleep periods may be too long, but compared to humans they’re okay.
Vision
I found the vision part to be the most finicky and time consuming. It helps to save problematic screenshots and write tests against them to ensure objects get detected as expected. During bot’s runtime we’ll use MSS library to take screenshots and perform object detection on them with OpenCV.
import cv2
from mss import mss
from PIL import Image
import numpy as np
import time
class Vision:
def __init__(self):
self.static_templates = {
'left-goalpost': 'assets/left-goalpost.png',
'bison-head': 'assets/bison-head.png',
'pineapple-head': 'assets/pineapple-head.png',
'bison-health-bar': 'assets/bison-health-bar.png',
'pineapple-health-bar': 'assets/pineapple-health-bar.png',
'cancel-button': 'assets/cancel-button.png',
'filled-with-goodies': 'assets/filled-with-goodies.png',
'next-button': 'assets/next-button.png',
'tap-to-continue': 'assets/tap-to-continue.png',
'unlocked': 'assets/unlocked.png',
'full-rocket': 'assets/full-rocket.png'
}
self.templates = { k: cv2.imread(v, 0) for (k, v) in self.static_templates.items() }
self.monitor = {'top': 0, 'left': 0, 'width': 1920, 'height': 1080}
self.screen = mss()
self.frame = None
First we start with the class. I cut out all of the template images for objects the bot will need to identify and stored them as png images.
Images are read with cv2.imread(path, 0) method, where the zero argument will read those images as grayscale, which simplifies the search for OpenCV. As a matter of fact, the bot will only work with grayscale images.
And since these template images will be used frequently, we can cache them on initialization.
Configuration for MSS is hardcoded here, but can be changed or extracted into a constructor argument if we want to.
Next we add a method to take screenshots with MSS and convert them into grayscale images in the form of Numpy arrays:
def convert_rgb_to_bgr(self, img):
return img[:, :, ::-1]
def take_screenshot(self):
sct_img = self.screen.grab(self.monitor)
img = Image.frombytes('RGB', sct_img.size, sct_img.rgb)
img = np.array(img)
img = self.convert_rgb_to_bgr(img)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
return img_gray
def refresh_frame(self):
self.frame = self.take_screenshot()
RGB to BGR color conversion is necessary, as while the MSS library will take screenshots using RGB colors, OpenCV uses BGR colors. Skipping the conversion will usually result in incorrect colors.
And refresh_frame() will be used by our game class to instruct when to fetch a new screenshot. This is to avoid taking and processing screenshots with every template matching call, as it is an expensive operation after all.
To match templates within screenshots we can use the built-in cv2.matchTemplate(image, template, method) method. It may return more matches that may not fully match, but those can be filtered out.
def match_template(self, img_grayscale, template, threshold=0.9):
"""
Matches template image in a target grayscaled image
"""
res = cv2.matchTemplate(img_grayscale, template, cv2.TM_CCOEFF_NORMED)
matches = np.where(res >= threshold)
return matches
You can find more about how different matching methods work on OpenCV documentation
To simplify work with matching our problem domain’s templates we add a helper method which will use a template picture when given its name:
def find_template(self, name, image=None, threshold=0.9):
if image is None:
if self.frame is None:
self.refresh_frame()
image = self.frame
return self.match_template(
image,
self.templates[name],
threshold
)
And while the reason is not obvious yet, let’s add a different variation of this method which would try to match at least one of rescaled template images. As we’ll later see, at the start of the round camera’s perspective may change depending on size of the opponent, making some objects slightly smaller or larger than our template. Such bruteforce method of checking templates at different scales is expensive, but in this use case it seemed to work acceptably while allowing to continue using the simple technique of template matching.
def scaled_find_template(self, name, image=None, threshold=0.9, scales=[1.0, 0.9, 1.1]):
if image is None:
if self.frame is None:
self.refresh_frame()
image = self.frame
initial_template = self.templates[name]
for scale in scales:
scaled_template = cv2.resize(initial_template, (0,0), fx=scale, fy=scale)
matches = self.match_template(
image,
scaled_template,
threshold
)
if np.shape(matches)[1] >= 1:
return matches
return matches
Game logic
There are several distinct states of the game:
- not started/starting
- started/in progress
- finished (result screens)
Since game linearly follows these states every time, we can use them to limit our Vision to check only for objects the bot can expect to find based on state it thinks the game is in.
It starts with not started state:
import numpy as np
import time
class Game:
def __init__(self, vision, controller):
self.vision = vision
self.controller = controller
self.state = 'not started'
Next we add a few helper methods to check if object exists based on template, and to attempt to click on that object:
def can_see_object(self, template, threshold=0.9):
matches = self.vision.find_template(template, threshold=threshold)
return np.shape(matches)[1] >= 1
def click_object(self, template, offset=(0, 0)):
matches = self.vision.find_template(template)
x = matches[1][0] + offset[0]
y = matches[0][0] + offset[1]
self.controller.move_mouse(x, y)
self.controller.left_mouse_click()
time.sleep(0.5)
Nothing fancy, the heavy lifting is done by OpenCV and Vision class. For object clicking offsets, they usually will be necessary as (x, y) coordinates will be for the top left corner of the matched template, which may not always be in the zone of object activation in-game. Of course, one could center the mouse on template’s center, but object-specific offsets work okay as well.
Next let’s run over indicator objects, and objects the bot will need to click on:
- Character’s name on the health bar (indicator whether the round is starting);
- Left corner post of the ring (to launch the player). Tried using character’s head before, but there are multiple characters in rotation as game progresses;
- “Filled with goodies!” text (indicator for pinata screen);
- “Cancel” button (to exit pinata screen);
- “Tap to continue” text (to skip “Missions” screen);
- “Next” button (to restart round);
- Rocket bar (indicator for when rocket boost can be launched);
These actions and indicators can be implemented with these methods:
def round_starting(self, player):
return self.can_see_object('%s-health-bar' % player)
def round_finished(self):
return self.can_see_object('tap-to-continue')
def click_to_continue(self):
return self.click_object('tap-to-continue', offset=(50, 30))
def can_start_round(self):
return self.can_see_object('next-button')
def start_round(self):
return self.click_object('next-button', offset=(100, 30))
def has_full_rocket(self):
return self.can_see_object('full-rocket')
def use_full_rocket(self):
return self.click_object('full-rocket')
def found_pinata(self):
return self.can_see_object('filled-with-goodies')
def click_cancel(self):
return self.click_object('cancel-button')
Launching the character is more involved, as it requires dragging the character sideways and releasing. In this case I’ve used the left corner post instead of the character itself because there are two characters in rotation (Bison and Pineapple).
def launch_player(self):
# Try multiple sizes of goalpost due to perspective changes for
# different opponents
scales = [1.2, 1.1, 1.05, 1.04, 1.03, 1.02, 1.01, 1.0, 0.99, 0.98, 0.97, 0.96, 0.95]
matches = self.vision.scaled_find_template('left-goalpost', threshold=0.75, scales=scales)
x = matches[1][0]
y = matches[0][0]
self.controller.left_mouse_drag(
(x, y),
(x-200, y+10)
)
time.sleep(0.5)
This is where the bruteforce attempt comes in to detect different scales of templates. Previously I used the same template detection using self.vision.find_template(), but that seemingly randomly failed.
What I ended up noticing is that depending on the size of the opponent affects camera’s perspective, e.g. first green bear is small and static, while brown bunny jumps up significantly. So for bigger opponents camera zoomed out, making the character smaller than the template, while on smaller opponents the character became larger.
So such broad range of scales is used in an attempt to cover all character and opponent combinations.
Lastly, game logic can be written as follows:
def run(self):
while True:
self.vision.refresh_frame()
if self.state == 'not started' and self.round_starting('bison'):
self.log('Round needs to be started, launching bison')
self.launch_player()
self.state = 'started'
if self.state == 'not started' and self.round_starting('pineapple'):
self.log('Round needs to be started, launching pineapple')
self.launch_player()
self.state = 'started'
elif self.state == 'started' and self.found_pinata():
self.log('Found a pinata, attempting to skip')
self.click_cancel()
elif self.state == 'started' and self.round_finished():
self.log('Round finished, clicking to continue')
self.click_to_continue()
self.state = 'mission_finished'
elif self.state == 'started' and self.has_full_rocket():
self.log('Round in progress, has full rocket, attempting to use it')
self.use_full_rocket()
elif self.state == 'mission_finished' and self.can_start_round():
self.log('Mission finished, trying to restart round')
self.start_round()
self.state = 'not started'
else:
self.log('Not doing anything')
time.sleep(1)
Fairly straightforward. Take a new screenshot about once a second, and based on it and internal game state perform specific actions we defined above. Here the self.log() method is just:
def log(self, text):
print('[%s] %s' % (time.strftime('%H:%M:%S'), text))
End result
And that’s all there’s to it. Basic actions and screens are handled and in the most common cases the bot should be able to handle itself fine. What may cause problems are the ad screens (e.g. Sales, promotions), unlocked items, card screens (completed missions), newly unlocked characters. But such screens are rare.
You can find the full code for this bot on Github.
While not terribly exciting, here is a sample bot’s gameplay video:
All in all this was an interesting experiment. Not optimal, but good enough.
Matching templates got us pretty far and the technique can still be used to automate remaining unhandled screens (e.g. unlocked items). However, matching templates works well only when perspective doesn’t change, and as we’ve seen from difficulties of launching the player - that is indeed an issue. Although OpenCV mentions Homography as one of more advanced ways to deal with perspective changes, for Burrito Bison a bruteforce approach was sufficient.
Even if template matching is a basic technique, it can be pretty powerful in automating games. While you may not have much luck in writing the next Counter Strike bot, but as you’ve seen thus far interacting with simple 2D objects and interfaces can be done fairly easily.
Happy gold farming!
Subscribe via RSS